
Why Your Chaos Experiments Give You False Confidence
You've done everything right.
You ran the hypothesis conversation. Your team discovered they had different mental models of how database failover works. You investigated the gaps. You fixed the connection pool configuration and the health check logic. You added monitoring for connection pool state.
Then you ran the experiment. Database fails over, circuit breaker trips, traffic routes to the replica, recovery completes in 30 seconds. Everything worked exactly as expected.
Three months later, the database fails during peak traffic. The system enters a death spiral. Circuit breakers trip and reset in rapid cycles. Connection pools exhaust. The replica becomes overloaded. Health checks start failing on healthy instances. Retries amplify the load. Recovery takes 23 minutes of manual intervention.
You tested this exact scenario. It worked perfectly. What happened?
You tested at the wrong load.
During your experiment, you ran with minimal traffic. Maybe some synthetic requests, maybe just manual testing. Production was handling 800 requests per second when the database failed.
That difference activated completely different system dynamics.
Why load changes everything
Systems with spare capacity behave as if they were deterministic. The same inputs produce the same outputs. Failures are reproducible. You can reason about what will happen and predict outcomes.
When systems run near their limits, they become non-deterministic. The Universal Scalability Law predicts this: contention and coherency costs cause non-linear performance collapse beyond critical load thresholds. Several mechanisms combine to create this shift.
Bimodal components. A cache either hits or misses. A circuit breaker is either closed or open. A connection pool either has available connections or is exhausted. A health check either passes or fails. Each is a binary state change that delivers radically different behavior
At low load, mode transitions don't matter much. A cache miss? The database has spare capacity. A circuit breaker opens? Other instances absorb the traffic. You have operational margin to absorb these transitions.
At high load, the same transitions cascade. A cache miss means the database is already near its limit, so the additional query causes queueing, which slows all queries, which triggers timeouts and retries. A circuit breaker opening means remaining instances are already near capacity, so redirected traffic pushes them over, causing their circuits to open.
Queueing effects. At low load, a cache miss adds one query to a queue of 10, and the impact is marginal. At high load, a cache miss adds one query to a queue of 10,000. The queue is already near capacity, and that additional query pushes it deeper into the non-linear region where waiting time explodes. This affects all subsequent requests, not just the one that missed.
Concurrency races. At low load, if two instances' circuit breakers both approach their trip thresholds, they trip at different times because request patterns vary enough. The first trips, load redistributes, the system absorbs it.
At high load, many instances approach thresholds simultaneously. One trips, load redistributes, and the redistribution pushes others over. They all trip within seconds of each other, and you get synchronized state transitions across your entire fleet rather than gradual failover.
Resource cascades. At low load, one slow request holds a thread a bit longer, but other threads are available and nothing cascades. At high load, one slow request holds a thread when no other threads are available. Incoming requests queue, the backup causes timeouts, timeouts trigger retries, and retries push thread pools deeper into exhaustion. Circuit breakers watching these timeouts approach their thresholds and trip. Three systems have now changed state because one request was slow at the wrong moment.
Timing variations. Which request becomes slow depends on factors you can't control. A database query lands on a disk performing compaction. A network packet gets delayed by congestion. A GC pause happens at an unfortunate moment. Under low load, these variations don't matter. Under high load, whichever request is slow can trigger a cascade.
Run the same chaos experiment five times at low load and you get consistent results. Run it five times at high load and you get five different outcomes. You're not seeing randomness. You're seeing emergent behavior from multiple interacting mechanisms whose states you can't precisely control.
Metastability: when resilience mechanisms prevent recovery
This pattern has a name: metastability. Researchers studying large-scale system failures identified this pattern and gave it a precise definition: failure states sustained by the system's own behavior, not by any ongoing external problem.
The trigger is gone. The database is back. The network is healthy. Every component passes health checks. But the system serves almost no useful work because the resilience mechanisms you built now create more load than the system can handle.
The cache can't rewarm because database load is too high. The circuit breaker can't close because retry load prevents downstream recovery. The connection pool can't replenish because failures happen faster than connections establish. The health checks can't pass because load redistribution keeps instances above the timeout threshold.
Your system occupies one of three states:
This diagram shows the relationship between load and goodput, with the three distinct system states.
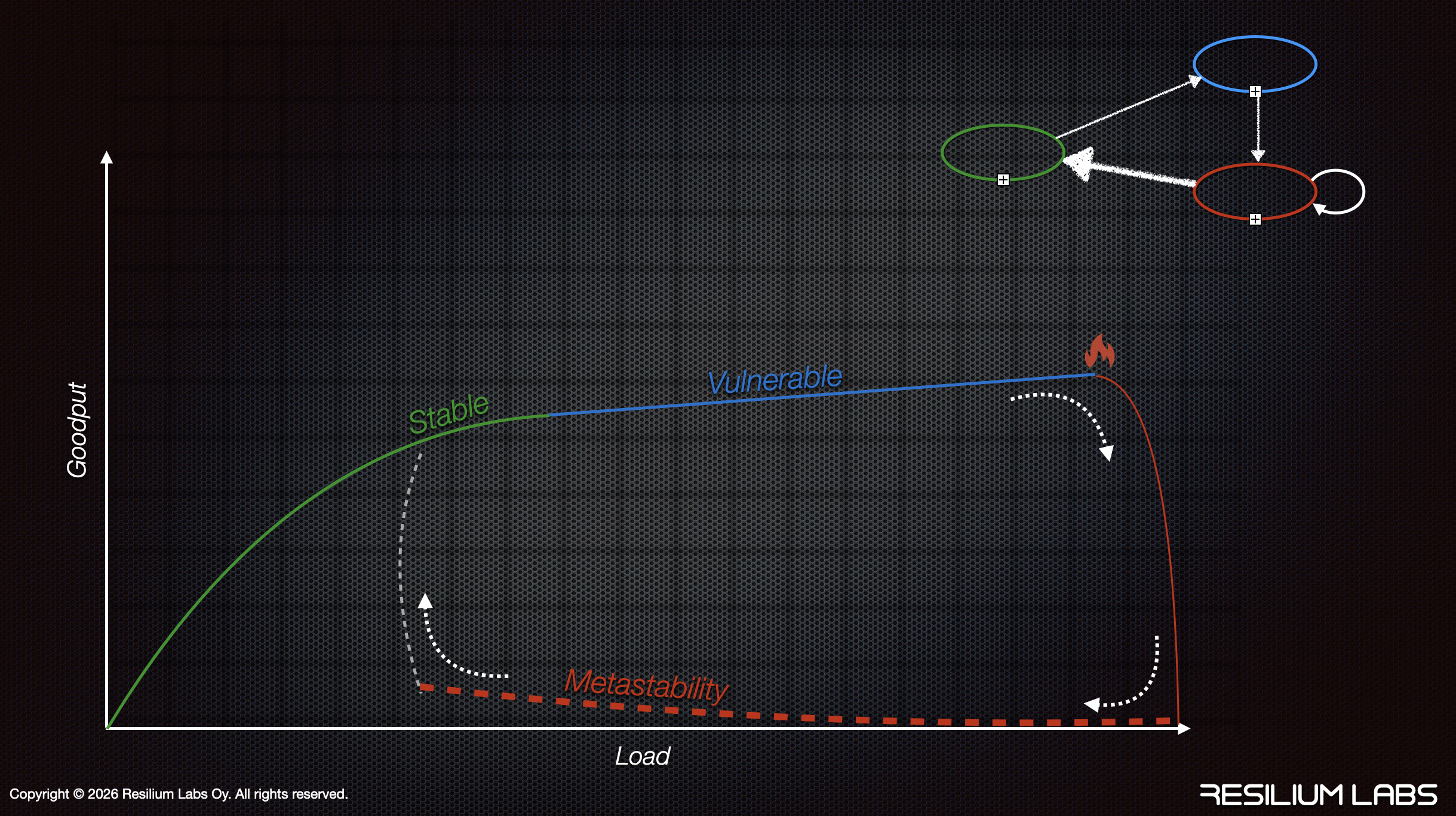
The green curve shows the stable state. Goodput scales with load. The system has spare capacity, so it can absorb triggers and self-recover. This is where your chaos experiments typically run.
The blue line shows the vulnerable state. The system operates efficiently near its limits. Goodput stays high, but there's little margin. A trigger (the fire icon) can push the system off this line.
The red dashed line shows metastability. Goodput collapses to near zero even though load remains high. The system has fallen off the curve entirely. Positive feedback loops prevent recovery.
The dotted arrows show what happens: a trigger pushes the system from vulnerable down into metastable failure, and it takes intervention (and reducing load significantly) to get back up to stable.
The state diagram in the corner shows the transitions. Stable can drift into vulnerable. Vulnerable can fall into metastable failure when a trigger activates sustaining effects. Metastable requires intervention to escape. You can't just remove the trigger and wait for recovery.
Two practices that should be one
Most organizations run load testing and chaos engineering as separate activities. The load testing team validates capacity. The chaos engineering team validates failure degradation. The two rarely meet.
Load testing without failure injection shows you how the system performs when nothing goes wrong. Chaos engineering without realistic load shows you how the system handles failures when it has spare capacity to absorb them. Neither tells you what happens when failures occur under production load.
That combination is exactly what production delivers. And that vulnerable region is exactly where you need to run your experiments to find the triggers that will collapse your system into metastability.
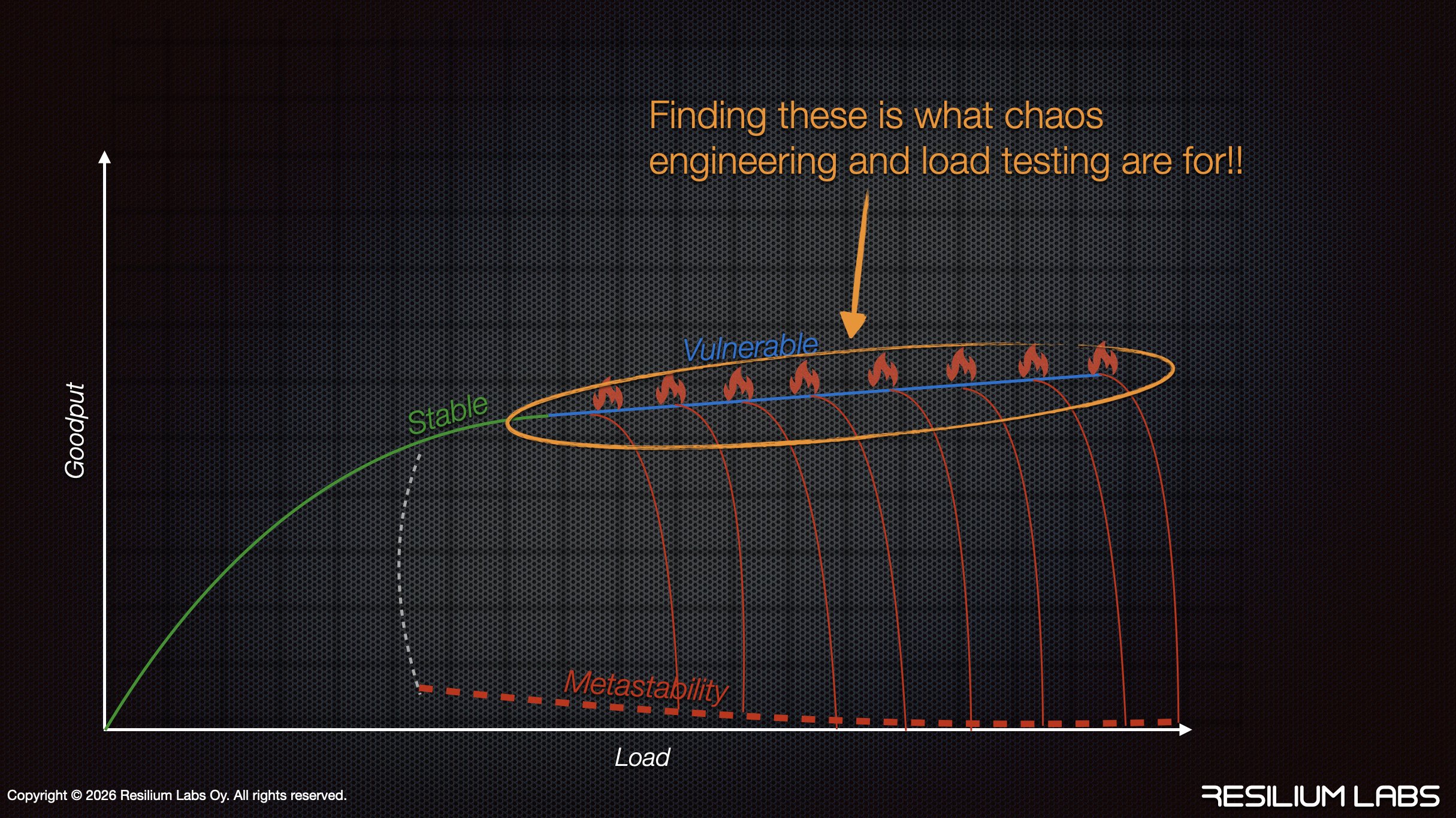
Finding those triggers before production does is what chaos engineering and load testing are for. But you can only find them by testing in the vulnerable region where production operates.
What this means for your experiments
The hypothesis conversation reveals gaps in your team's mental models. Investigation and fixing address the knowable problems. But there's a third category we didn't fully explore: emergent behavior that only appears under load.
When you design experiments for uncertainty gaps, the ones where behavior emerges from component interactions, you need to test under realistic load. Not "some" load. Production-equivalent load.
Your experiment design from the last newsletter asked: "We want to know how our application's retry logic interacts with database failover under realistic traffic load."
Realistic traffic load is the key phrase. If you test at 50 requests per second and production runs at 800, you're testing a different system. The stable regime behaves deterministically. The vulnerable regime behaves non-deterministically because queueing effects amplify, concurrency races synchronize, resource cascades chain, and timing variations that didn't matter suddenly determine outcomes.
Same code. Same architecture. Same failure injection. Completely different outcomes.
Try this
Take one of the uncertainty gaps you identified in your hypothesis conversation. Design the experiment as we discussed, with specific predictions about timing, behavior, and recovery.
Then ask yourself what load level does production actually experience during peak hours? Can you run your experiment at that load level?
If you can't, you're testing in the stable region. Your results will give you false confidence about triggers that only activate in the vulnerable region where production operates.
You want to find those fire icons in the diagram before production finds them for you. That requires chaos engineering and load testing together.
Until then,
Adrian